プログラミング知識ゼロからGoogleColaboratoryでAI始めてみた(5)

(前回記事の続きです)
お久しぶりです。IIUの鎌田です。
今回でGoogleClaboratoryはついに最終回です!
ほぼ1年越しでやってきましたが12月になると2022年も早かったなーとしみじみ思います。
さて、最終回はお待ちかねの学習と検証回です!
■学習フェーズ
まずは下記コードをコピペしてください。
- ################################
- ############# 学習 #############
- ################################
- import keras
- import glob
- import numpy as np
- import os
- from keras import models, optimizers
- from keras.applications.vgg16 import VGG16
- from keras.utils import np_utils
- from keras.models import Sequential
- from keras.layers.convolutional import Conv2D, MaxPooling2D
- from keras.layers import Dense, Dropout, Activation, Flatten, BatchNormalization
- from keras.preprocessing.image import ImageDataGenerator
- from sklearn.model_selection import train_test_split
- from PIL import Image
- from tensorflow.keras.optimizers import SGD
- from keras.callbacks import LearningRateScheduler
- from keras.callbacks import ModelCheckpoint
- ##設定#################################################################################################
- batch_size = 32 #ニューラルネットワークに何枚ずつ画像データを投入して学習させるか(とりあえず32で)(4の倍数だとだいたい上手くいきます)
- nb_classes = 3 #評価数を指定
- nb_epochs = 10 #用意した画像データを何周させるか
- test_size = 0.2 #用意した画像の何%を評価用に使うか(記入例0.20 = 20%)
- image_width = 224 #画像の幅
- image_height = 224 #画像の高さ
- #学習に使う画像フォルダを評価別に指定
- Excellent = “drive/My Drive/画像認識/初期データ/○”
- Average = “drive/My Drive/画像認識/初期データ/△”
- Bad = “drive/My Drive/画像認識/初期データ/×”
- folder = [Excellent,Average,Bad] #上記フォルダに対応させる(4フォルダあるなら4つ、5なら5)
- ClassNames = [“○”,“△”,“×”] #検証時に表示したいラベルを指定
- #学習モデルの格納場所とファイル名を指定
- json_file = ‘drive/My Drive/codeモデル/code_cnn_model1.json’ #学習モデルを使う際に必要なファイル(自動生成)
- best_weights = ‘drive/My Drive/codeモデル/best_weights1.h5’ #誤差関数が一番低い部分の学習モデル
- last_weights = ‘drive/My Drive/codeモデル/last_weights1.h5’ #最終エポックまでの学習モデル
- #######################################################################################################
- X = []
- Y = []
- for index, name in enumerate(folder):
- dir = “./” + name
- files = glob.glob(dir + “/*”)
- for i, file in enumerate(files):
- image = Image.open(file)
- data = np.asarray(image)
- X.append(data)
- Y.append(index)
- X = np.array(X)
- Y = np.array(Y)
- X = X.astype(‘float32’)
- X /= 255.0
- # 正解ラベルの形式を変換
- Y = np_utils.to_categorical(Y, nb_classes)
- # 学習用データとテストデータ
- X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size)
- # 学習率の変更
- learn_schedule=0.9
- class Schedule(object):
- def __init__(self, init=0.001): # 初期値定義
- self.init = init
- def __call__(self, epoch): # 現在値計算
- lr = self.init
- for i in range(1, epoch+1):
- lr *= learn_schedule
- return lr
- def get_schedule_func(init):
- return Schedule(init)
- lrs = LearningRateScheduler(get_schedule_func(0.001))
- mcp = ModelCheckpoint(filepath=best_weights, monitor=‘val_loss’, verbose=1, save_best_only=True, mode=‘auto’)
- # CNNを構築
- vgg_conv = VGG16(weights=‘imagenet’, include_top=False, input_shape=(image_width, image_height, 3))
- for layer in vgg_conv.layers[:-4]:
- layer.trainable = False
- model = models.Sequential()
- model.add(vgg_conv)
- model.add(Flatten())
- model.add(Dense(1024, activation=‘relu’))
- model.add(Dropout(0.5))
- model.add(Dense(nb_classes, activation=‘softmax’))
- model.summary()
- # コンパイル
- model.compile(optimizer=SGD(lr=0.001), loss=‘categorical_crossentropy’, metrics=[“accuracy”])
- print(model)
- #訓練
- history = model.fit(X_train, y_train, batch_size=batch_size, epochs=nb_epochs, verbose=1, validation_data=(X_test, y_test), shuffle=True, callbacks=[lrs, mcp])
- #評価はevaluateで行う
- score = model.evaluate(X_test, y_test, verbose=0)
- print(‘Test loss:’, score[0])
- print(‘Test accuracy:’, score[1])
- #学習モデルを保存
- json_string = model.to_json()
- json_string += ‘##########’ + str(ClassNames)
- open(json_file, ‘w’).write(json_string)
- model.save_weights(last_weights)
- model.add(Dense(nb_classes, activation=‘softmax’))
- model.summary()
めちゃめちゃ長いコードですいません
これでも最低限学習できるようなシンプルなコードになっています。
早速使い方ですが、前回のコードと同じく#の中の設定をいじるだけにしました。
すべてコード上の説明通りなのですが、気を付けるポイントとして
画像サイズとラベルと学習モデルの保存先はしっかり確認してください。
実行するとプログレスバーで学習の進行度を教えてくれて、設定したエポック数分処理が終わると完了です。
■モデル精度確認フェーズ
学習モデルができたら下記コードを実行してみて下さい。
- ################################
- ############ 正解率 ############
- ################################
- import matplotlib.pyplot as plt
- acc = history.history[‘accuracy’]
- val_acc = history.history[‘val_accuracy’]
- nb_epoch = len(acc)
- plt.plot(range(nb_epoch), acc, marker=‘.’, label=‘acc’)
- plt.plot(range(nb_epoch), val_acc, marker=‘.’, label=‘val_acc’)
- plt.legend(loc=‘best’, fontsize=10)
- plt.ylim(ymin=0) #ymaxは変えずに、yminだけ変更
- plt.grid()
- plt.xlabel(‘epoch’)
- plt.ylabel(‘acc’)
- plt.show()
このコードを実行すると写真のような正解率をグラフで確認することが出来ます。
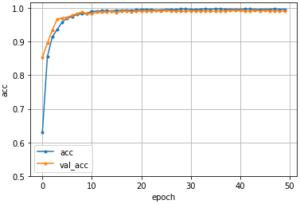
図1 正解率の出力
エポックごとに正解率が分かるのでちゃんと学習できているかどうかを確認することが出来ます。
このグラフがぐちゃぐちゃだったり、最終エポックの正解率が低かったりすると
モデルの精度が悪いので、学習の設定や画像データを見直してみて下さい。
ところでこのグラフ、2種類ありますが
青は学習に使ったデータの正解率青は学習に使ったデータの正解率で、オレンジは評価用(validation)データでの正解率を示しています。
学校のテストの時に一度解いたことがある問題と全く一緒だと簡単ですよね。
逆に習っている分野だけどそれが応用された問題だと難しかったりします。
それと同じで、AIも学習したのと同じ画像で評価するのは簡単ですが、学習に使ってない画像で評価するのは難しいわけです。
そのため学習していない画像でも、評価できるモデルが作れているか確認できるようになっています。
■検証フェーズ
最後に学習モデルを使った検証です。
下記コードを使って検証しました。
- ################################
- ############# 検証 #############
- ################################
- import os.path as op
- import numpy as np
- import matplotlib.pyplot as plt
- from keras.preprocessing.image import load_img, img_to_array, array_to_img
- from keras.models import model_from_json
- ##設定#################################################################################################
- json_file = “drive/My Drive/codeモデル/code_cnn_model1.json” #jsonファイルを指定
- weights = “drive/My Drive/codeモデル/best_weights1.h5” #学習モデルを指定
- test_image = “drive/My Drive/画像認識/テストデータ/code/ばつ/” #テスト画像が入ったフォルダを指定
- image_width = 224 #画像の幅(テスト画像もサイズを統一させておくこと)
- image_height = 224 #画像の高さ
- #######################################################################################################
- def TestProcess(imgname):
- modelname_text = open(json_file).read()
- json_strings = modelname_text.split(‘##########’)
- textlist = json_strings[1].replace(“[“, “”).replace(“]”, “”).replace(“\'”, “”).split()
- model = model_from_json(json_strings[0])
- model.load_weights(weights)
- img = load_img(imgname, target_size=(image_width, image_height))
- TEST = img_to_array(img) / 255
- plt.imshow(img)
- plt.show()
- np.set_printoptions(suppress=True)
- pred = model.predict(np.array([TEST]), batch_size=1, verbose=0)
- print(“>> 計算結果↓\n” + str(pred))
- print(“>> この画像は「” + textlist[np.argmax(pred)].replace(“,”, “”) + “」です。”)
- while True:
- while True:
- imgname = input(“\n>> テスト画像のファイル名を入力して下さい(「end」を入力して終了) : “)
- if imgname != “end”:
- imgname = test_image + str(imgname)
- if op.isfile(imgname) or imgname == “end”:
- break
- print(“>> そのファイルは存在しません!”)
- if imgname == “end”:
- print(‘>> 終了しました。’)
- break
- # 関数実行
- TestProcess(imgname)
まずは、テスト用の画像を数枚用意してGoogleDriveのフォルダに入れてください。
そしたらコードの設定の部分で自動生成されたjsonファイルと学習モデルを指定します。
こちらの方が過学習を防いだ汎用的なモデルになっています。
これで実行すると、、、
「テスト画像のファイル名を入力して下さい」と表示されるので、拡張子を含めてテストしたい画像を入力して下さい。
そうすると私の場合はですが、下記画像のように○△×で評価してくれます。

図2 検証結果例
以上が学習から検証までのやり方です!
図2に「前回」「今回」とあるように、ここから私は何度も学習モデルを作成して検証を重ねました。
カスタマイズ要素としてはいくつかあります。
- 画像の枚数
- 画像のサイズ
- 水増しした場合としなかった場合
- 水増し枚数
- エポック数
- 評価クラスの数
などなど。
これらを変えてみて自分の理想の学習モデルを作ってみて下さい。
以上、GoogleColaboratoryでのAIの使い方講座は終了です。
ここまで読んで下さりありがとうございました。
ここからより良きAIライフが始まるのを祈っています。
それではまた別のブログで会いましょう!